
About 3 weeks ago I wrote about Open Blogging, blogging with a DVCS hosted on a community server as backend. Well, I also wrote that I would really love to have something similar for my own site. Somehow the idea stuck and this morning I finally flipped the switch.
The approach I took is probably a bit of a brain-f*ck but hopefully at least a bit interesting to those of you who want to have a blog out of a DVCS like Git :-)
Every time I think about writing a new blog post, I open up the nearest text editor - be it TextMate, VIM, Notepad++ etc. - and start writing in it. But once I’m done I have to copy/paste the whole post into a webinterface, which kind of feels unnatural to me. So pretty much a year ago (I think on day 2 of EuroDjangoCon 2009) I wrote a small API for my blog using piston together with a small CLI client I could use for updating a post.
Well, I used it for a couple of posts and then mostly forgot about it. It simply didn’t offer enough benefit outside of not copy/pasting stuff anymore, and I just went back to writing in Textmate first and then moving the content over.
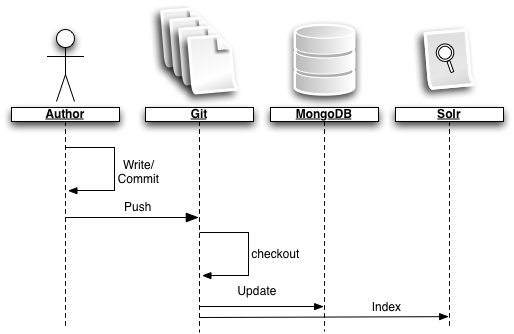
But for the last couple of weeks I’ve spent a bit of time rewriting the site once again. Visually you won’t notice all that much (hopefully nothing) except for comments now being served by Disqus. But under the hood I basically replaced the whole engine using Git as primary storage for blog posts and pages like the “About” page.
What happens from there is a bit more complicated: When a post is updated in the master-branch, a post-receive hook-script checks what kind of content was changed (post or page) and sends the updated content right into a mongodb which a Django webapps then uses to render the post on the site.
The database
So I didn’t quite leave all thoughts of a database behind but it only acts as secondary storage for presenting the content (in order to get a bit of caching and some simple aggregation facilities that I don’t have to update all the time by hand).
Besides, I was already using MongoDB for my collection-app and rewriting that didn’t feel right to me (except for porting it to mongoengine). I also thought about using CouchDB, but again for because of the pre-existing mongo-integration I abandoned that idea.
Solr
As kind of a 3rd layer (or a layer right next to the database) sits a small solr server that I’ve already been using previously for the search feature on this site. Since the excellent django-haystack is now no longere an option, I just went straight with pysolr and had some great fun. Now solr not only acts as the search engine but also provides the related blog posts.
The content
What’s left is the actual post-structure. For this I went with a simple folder-per-post structure and each folder usually only contains 2 files: An index.(html|mdown|rst) file containing the actual post and a metadata.json file that houses metadata like tags, language etc.
This way I can also put file related to each post - like images - right next to the actual content, which makes previewing the whole post offline much easier and also keeps the whole folder-structure rather clean.
The learning experience
First of all, writing all this was great fun but I’ve also again learned a couple of things:
-
Interacting with Git through abstraction layers an wrapper libraries can be quite a pain and in many situations it’s not worth it for me. So for simple operations I just went back to the subprocess module and everything worked just fine.
-
Never trust datetime objects. Especially not when importing data and you are not sure how the timezone is ported over (if even that). dateutil and the calendar module are a great help here when converting the various structures from and to UTC.
-
Always write your reduce function for MongoDB in an idempotent way as stated on the MongoDB wiki or deal with quite unexpected results. This one bit me when writing the tagcloud and monthly-archive block (which should return the year as key and all months that contain a post as a list but then returned the years and a whole bunch of nested objects with the months somewhere around the leaf nodes).
-
mongoengine lets you specify a collection to be used for its top-level documents. By default a document “Post” would end up in a collection named “post”, which kind of felt unintuitive to me (don’t get me started on table-names ;-)) so just setting
meta['collection']='posts'on the Post class changed that.
Well, that’s about it. Now I can just hope that I didn’t mess up something somewhere deep in the converter code (not like last night …) ;-)
Do you want to give me feedback about this article in private? Please send it to comments@zerokspot.com.
Alternatively, this website also supports Webmentions. If you write a post on a blog that supports this technique, I should get notified about your link 🙂